Part 2: Felix Research’s Clean Data proposal

Who has the right to create or “create”?
My CEO sent me a quote tweet (or Xeet, or post, or whatever the correct nomenclature currently is) about Nano Banana and AI in general and told me to blog about it. The tweet:
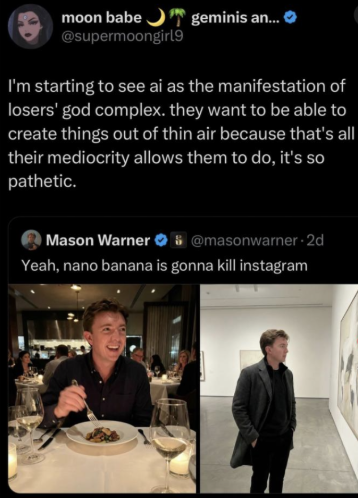
This is a Xeet after all, so we’ll gloss over the misappropriation of the generalised “AI” label to refer solely to generative AI. We also won’t question too closely the aptness of “god complex” in this situation. A God Complex is a delusion of grandeur and superiority - albeit, the link to creation is elegant.
We can understand the sentiment of this tweet as:
“Generative AI’s main use case is ostensibly empowering the lazy, the untalented and the unqualified to create things they have no business creating. If they had any business creating those things, they would value and invest in the journey/ slog and consequentially they would become initiated via their own passion and aptitude – at which stage they would have little to no interest in using genAI. Instead, the mediocre reap the fruit of the labour of the contributors, whose uncredited and uncompensated work trained these models and is the foundation of anything the interlopers go on to “create”.
Or maybe I’m completely incorrect in my interpretation. For the purposes of this piece, however, we will work with the above.
What's Wrong with Using AI to "create"?
A) Energy usage and ESG concerns. These are practical issues that are relatively simply handled - if the relevant parties choose to handle them. This will not be the focus of the piece. The more slippery issue is, by nature, harder to name and implied in @supermoongirl9's tweet. I will attempt to identify, name and unravel it within my breakdown of the below.
B) Plagiarism & lack of originality. Why is this an issue? Because of a lack of renumeration and credit for the original contributors. However, this is a normal (not good, but also not unique) function of capitalism.
The issue with centring stolen/ uncredited/ uncompensated IP in discussions about genAI use, is that such a thing is a practical issue in the domain of contract law, not morality (apologies to those who think of the two as tied).
Consider the following situation: You join an organisation and sign your employment contract, which means signing over your work-related IP to your employer. During your tenure, you create a revolutionary internal program that saves your company hundreds of thousands. For this, you get a promotion and raise (which is a fraction of the revenue you have generated). After your exit, your employer repackages and sells the program to third parties and you don’t see a penny of that sales revenue because it is not and was never your IP.
If we are going to delineate the concept of credit, we must figure out how we value visibility/ exposure. Consider the structure of author contributions to a scientific journal – these are usually not financially compensated. If LLMs had an academia-style inbuilt citation system that assigned credit to sources of training data, would this be a solution? Partly, but there seems to be an additional aspect to the general public's discomfort with "AI Creators" and I suspect it is the intangible reward that is acclaim and cultural currency.
The dichotomy we are presented with is: "pick a side - you either think genAI is like traditional media production but BETTER (superlative of the same thing) or you think it’s outright THEFT".
Mightn’t there be a third option? That genAI is a different (value neutral) kind of creation?
To draw on a parallel, let’s look at driving. There is no moral implication associated with only knowing how to drive automatic (it’s important the reader knows that all three men in my office were quick to disagree with this) but it’s understood that there is a fundamental skill that manual drivers possess, which automatic drivers lack. This isn’t an issue because the machine compensates for the gap in the latter’s skillset. The question is therefore purely practical – are you road safe and is the end result competence?
But if we were discussing Formula 1 drivers, the conversation would surely be different; namely being one to do with desert and reward, rather than practical outcomes.
What I’m getting at here, is that acclaim, recompense and appreciation for effort (i.e. components of credit) are muddying factors. "If you want to enter the market, don't cheat" is the sentiment here. Don't try to enter the market and you can do what you like.
These nuances within the wider umbrella of credit bring to mind two parallels:
1) The invention of the camera.
This critique boils down to the above "you're cheating and unskilled" argument. But perhaps what is emerging, similar to the advent of photography, is a new type of creation and therefore a new kind of skill?
Is the invention of genAI to media production what the invention of photography was to traditional art? Or is the invention of genAI to media production what piracy is to media production companies? Prompt engineering is a skill (spoiler: it's philosophy (more specifically, theory of mind)) that requires some effort and development and perhaps deserves some credit. This, however, does not answer the issue at the heart of the second parallel...
2) "Reality stars are (undeservedly) famous for being famous (doing nothing)!"
We can take this critique to mean "We/ society doesn't value the "skill" which is being rewarded here". The response to this sentiment is arguably "So?" Our hypothetical complainant might level either of the following retorts: i) we should care to police that which contributes to cultural rot ii) we should be wary of creating incentives (like attention and resultantly money) to degrade culture.
The problem is, “rot” is subjective and even if we could reach consensus on such a thing, when something is lucrative, or even just profitable, that is a factual demonstration of how this given thing is valued by our society.
So how do we decide what is permissible and what isn’t? Maybe we examine risk and impact ad hoc and determine what our societal values are? Lofty and easier said than done! Do we posit that intellectualism is virtue whilst anti-intellectualism is vice and use this as a rubric? What does this mean for productivity tools and AI given MIT's findings?
Enter Felix Research's philosophy of Augmented Intelligence. Wherein keeping a human-in-the-loop leads to the prioritisation of both clarity and speed.
Practicalities of Avoiding Slop & FRx's Clean Data Proposal
Thus far, we have looked at AI slop as a general phenomenon. If we examine it in the context of enterprise use, AI slop is not just an irksome source of noise, but rather a technical challenge and source of risk.
Existing genAI systems create an environment where, frankly, plausibility of output is conducive to complacency in end users. The generated outputs sound correct, especially when the work is shallow or unfamiliar, however using an LLM for deep research, or for an esoteric subject that you have expertise in will quickly reveal its limitations. If an uncritical LLM user is working in a team, sharing their work and findings with others, this makes it all the more difficult to distinguish accurate output from misinformation further down the line.
The systems that generate slop are often well-engineered at their core, but poorly supervised, unexamined and unchecked. What they lack is structure. For organisations that depend on reliable intelligence, particularly in financial contexts, this absence of rigour is untenable.
Felix Research’s proposal in favour of clean data addresses this challenge directly. We put forth the below introductory framework for keeping AI fast, trustworthy and transparent by embedding governance principles into its foundations. The simple truth is that speed is only an advantage if you can trust your outputs; when AI systems produce results that cannot be traced or validated, acceleration becomes a liability. Clean data restores balance by ensuring that every layer of automation is grounded in provenance and accountability.
"A primary concern for enterprise data governance is the lineage of information" notes Ryan Daws in his recently published article on AI and threats to business data accuracy. Every dataset carries a lineage, and knowledge of that lineage is essential to judging the reliability of any conclusion derived from it.
Provenance is therefore the first pillar of clean data in the context of AI for enterprise use. Like a house of cards, if we lack this clarity on the fundamental layer that is good data provenance, outputs cannot be meaningfully verified. Clean data therefore depends on disciplined data hygiene: structured ingestion, active validation and documented review. These are long-standing practices in Business Intelligence, but they must now become rigorously enforced standards in AI.
The second pillar is Ethics-by-Design. Responsible AI cannot be achieved by policy alone; it must be built into systems architecture. This means defining transparent parameters for how data is collected, processed and applied, as well as ensuring that accountability is distributed rather than deferred. In finance, where AI systems could conceivably shape regulatory reporting and investment decisions in the future, such clarity is not a moral preference but a compliance necessity.
Our third pillar is Hybrid Reasoning. By combining symbolic AI (which uses explicit rules and logic) with generative models /unsupervised components that learn and adapt, organisations can achieve both speed and interpretability. Symbolic reasoning provides a structured framework for traceability and compliance whilst generative and unsupervised systems add flexibility and contextual understanding. Together, they create an AI stack capable of producing insight that is dynamic yet dependable.
AI Slop vs Clean Data AI Table
Dimension | AI Slop | Clean Data AI |
Output Quality | Superficially fluent, factually fragile | Transparent, traceable, and domain-specific |
Data Integrity | Unverified, poorly sourced, feedback-looped | Curated, validated, and provenance-tracked |
Governance Approach | Ad hoc, siloed oversight | Cross-functional governance (Compliance + BI + Engineering) |
Human Role | Removed from the loop, human as observer | Central to the loop, human as sense-maker |
Architecture | Purely generative, prone to hallucination | Hybrid symbolic + probabilistic reasoning & RAG systems |
Compliance Risk | High, opaque decisions and unverifiable outputs | Low, auditable data lineage and deterministic logic |
Business Value | Volume-driven productivity illusion | Decision-ready insight and reputational resilience |
At Felix Research, we seek to create a centralised workflow environment wherein data lineage, validation and reasoning coexist seamlessly. Analysts should be able to move quickly without surrendering oversight and organisations should be free to innovate without compromising trust.
Our philosophy is not a rejection of automation but a refinement of it. We understand that innovation with lacklustre governance is unsustainable and that acceleration without clarity leads nowhere useful. By treating data integrity as an enabler rather than a constraint, institutions can build systems that are both efficient and ethical.
Watch this space.